The Claude Code Skill Creator Now Has Evals (And My Skills Finally Have Proof They Work)
Here’s a confession.
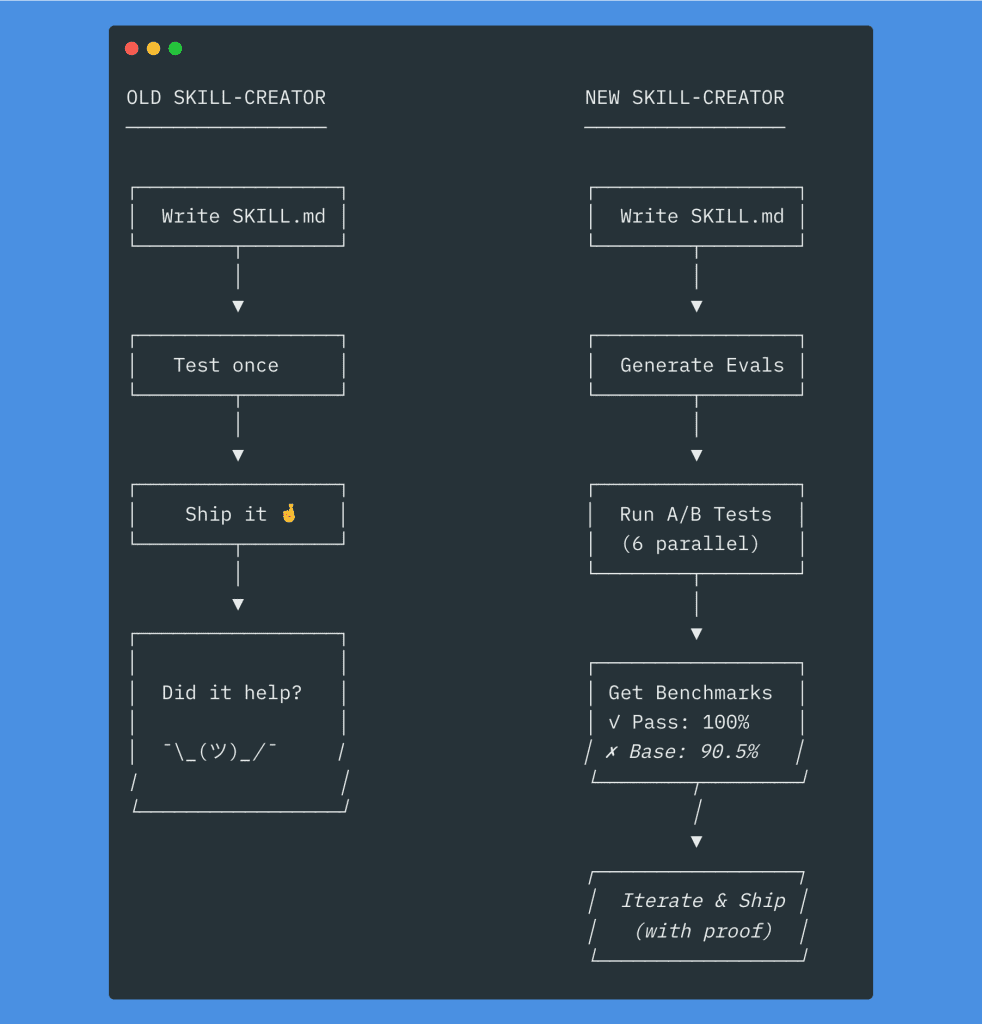
For months, I’ve been building Claude Code skills with what I can only describe as the “hope and pray” methodology. Write the SKILL.md. Test it once. Ship it. Whisper a small prayer to the LLM gods. Move on with my life.
Did the skill actually trigger when it should? ¯\_(ツ)_/¯
Did it make Claude’s output better? Honestly… no idea.
I’ve been using skills since they were added to Claude Code — and until last week, I had zero way to answer either of those questions.
(Stay with me. This story has a happy ending.)
.
.
.
The Problem With Skills (That Nobody Wants to Admit)
Here’s the thing about Claude Code skills: they’re just text prompts. Fancy, well-organized text prompts — but text prompts nonetheless.
And text prompts don’t come with test suites.
I’ve built dozens of skills over the past few months. Frontend design patterns. WordPress security checklists. Newsletter writing styles. Documentation generators. Each one followed the same ritual:
- Write a SKILL.md file
- Test it manually (once, maybe twice if I’m feeling thorough)
- Hope it works
- Wonder — weeks later — if it’s actually triggering
- Wonder — with increasing anxiety — if it’s helping when it does trigger
- Have absolutely no data to know either way
The old skill-creator plugin could generate skills for you, which was genuinely useful. But it had no evals. No testing. No benchmarks. You’d create a skill, and then… that was it. Cross your fingers, close the terminal, pretend everything was fine.
I kept using skills because they felt useful. But I couldn’t prove it. I couldn’t point to a number and say “this skill improves output quality by 9.5%.”
Every skill I created was a guess. A lovingly crafted, well-intentioned guess — but a guess.
The Upgrade That Changes Everything
The Claude Code skill creator plugin just got a massive upgrade. And honestly? It solves the exact problem I’ve been complaining about for months.
The new version adds something skills have never had: a testing and benchmarking layer.
Here’s what the updated skill creator can do:
- Create skills from your requirements (same as before)
- Generate evals — actual test cases — automatically
- Run parallel A/B benchmarks comparing skill vs. baseline Claude
- Optimize trigger descriptions so your skill activates when it should
- Iterate until the skill measurably improves output
That last part bears repeating: measurably improves output. With numbers. And charts. And side-by-side comparisons.
Let me show you how this works with a real skill I built last week.
.
.
.
Building a WordPress Security Review Skill (The Whole Process)
I built several WooCommerce plugins — which means security reviews are part of my regular workflow. But Claude’s baseline security reviews felt… inconsistent. Sometimes thorough, sometimes surface-level. No predictable structure.
Perfect candidate for a skill.
Step 1: Describe What You Want
I asked Claude Code to create a skill using the skill-creator plugin:
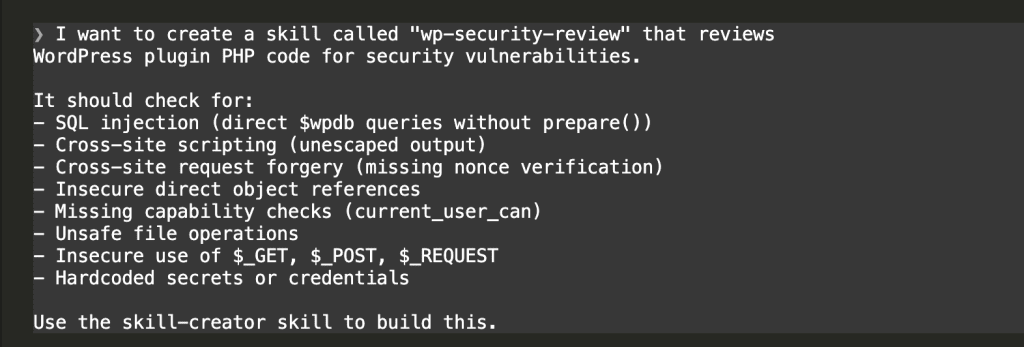
My prompt included the specific vulnerability types I wanted covered: SQL injection, XSS, CSRF, missing nonce verification, insecure $_GET/$_POST usage, and more.
Step 2: The Skill Creator Explores Your Codebase
Here’s where things get interesting.
Claude loaded the skill-creator skill and immediately started exploring my project:
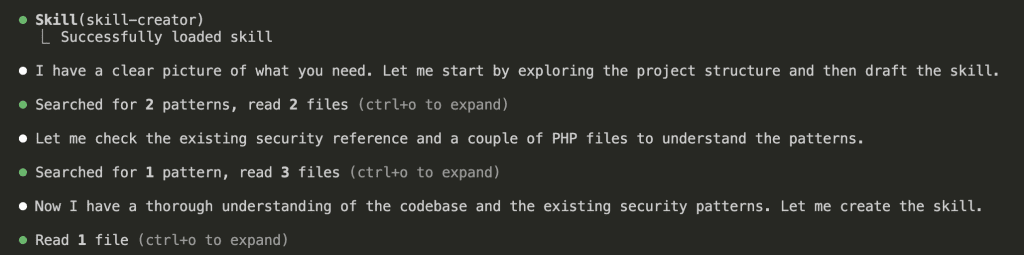
The skill-creator looked at my existing code, found security patterns already in the project, and used that context to build a skill tailored to my codebase. (Not a generic one-size-fits-all approach.)
Step 3: The Generated Skill
Claude wrote 330 lines to .claude/skills/wp-security-review/SKILL.md:
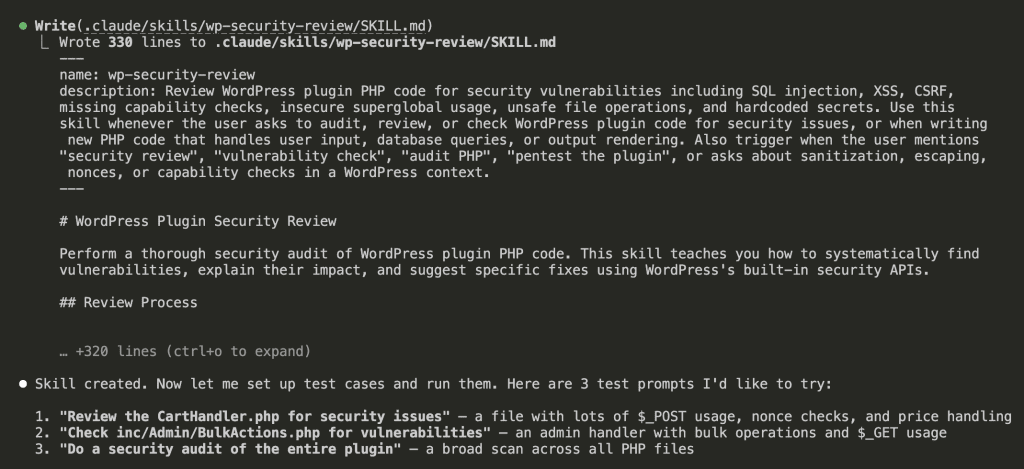
The skill included:
- A detailed trigger description (optimized for when Claude should activate it)
- A vulnerability checklist with 8 categories
- WooCommerce-specific nuances — like
wc_price()double-escaping and WC Settings API nonce delegation - Structured output format with severity ratings
All good stuff. But here’s the thing: a skill is only as good as its results.
And until now, I had no way to measure those results.
.
.
.
The Part That Made Me Actually Stop and Stare: Evals
After creating the skill, Claude immediately said: “Now let me set up test cases and run them.”
Wait, what?
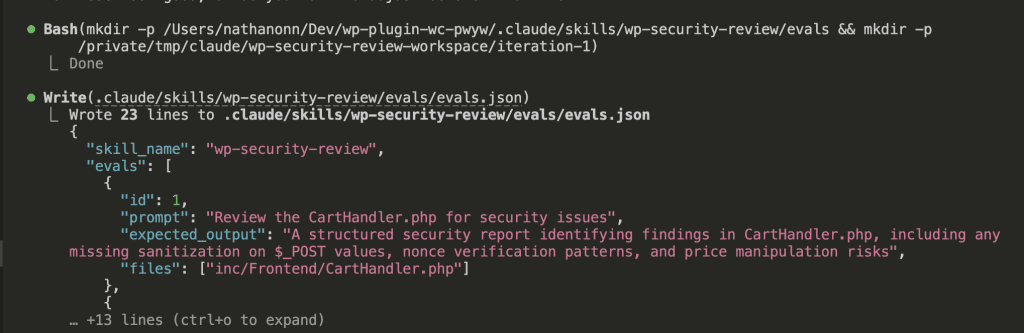
The skill-creator generated an evals.json file with:
- 3 test prompts targeting different aspects of my plugin
- Expected outputs for each test
- Specific files to review
And then — and I genuinely did not expect this — it launched parallel agents.
Running 6 Agents Simultaneously
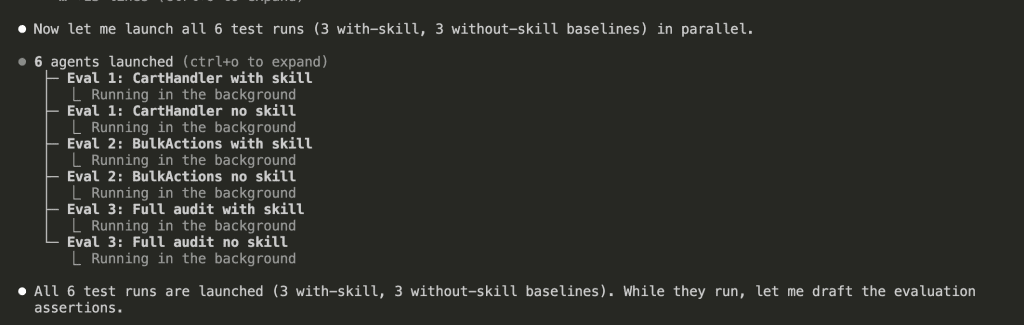
Claude launched 6 parallel agents:
- 3 running the tests with the skill
- 3 running the same tests without the skill (baseline Claude)
While those ran in the background, Claude drafted the evaluation assertions:
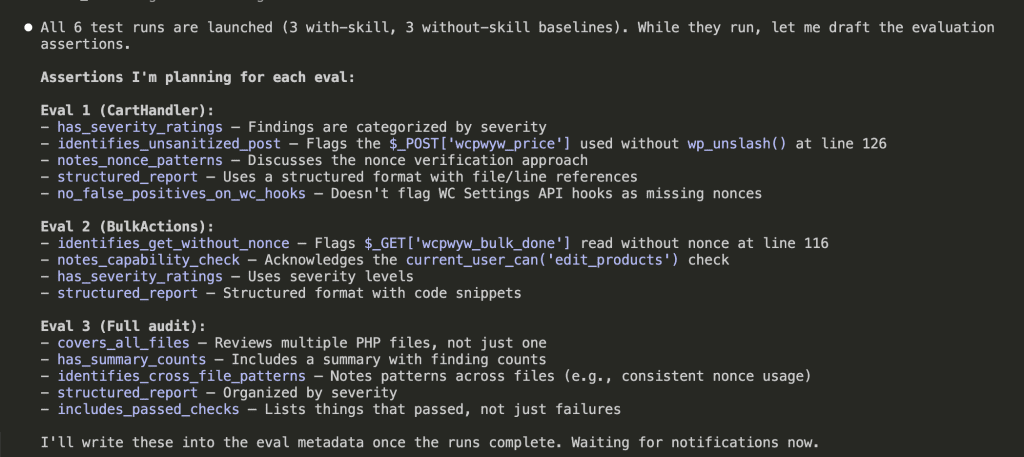
Each test case had specific pass/fail criteria:
has_severity_ratings— Findings must be categorized by severityidentifies_unsanitized_post— Must flag$_POST['wcpwyw_price']at line 126no_false_positives_on_wc_hooks— Must NOT flag WC Settings API as missing noncesincludes_passed_checks— Must list what passed, not just failures
(Real criteria. Measurable criteria. I could have cried.)
.
.
.
Results Rolling In
As the agents completed, results started appearing:
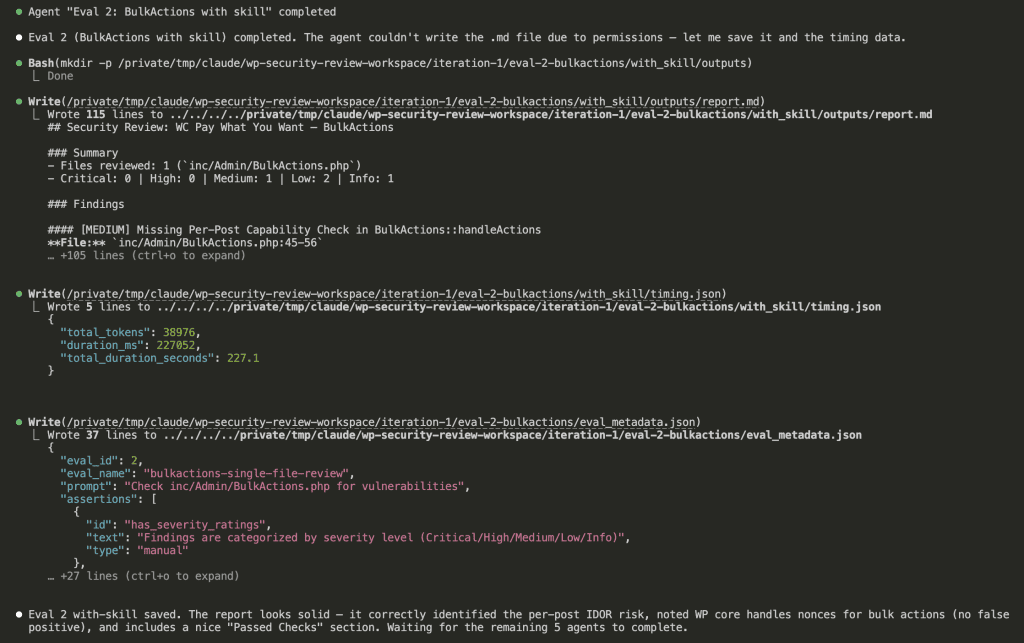
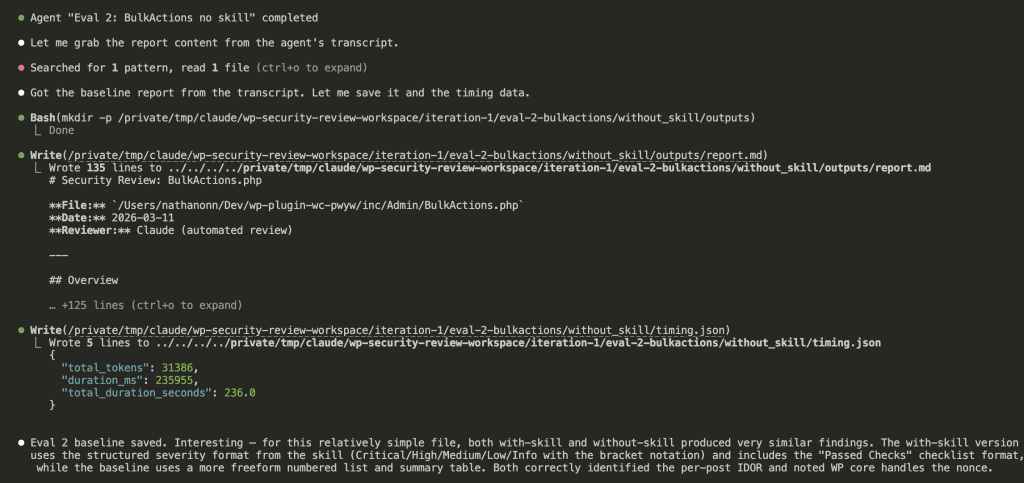
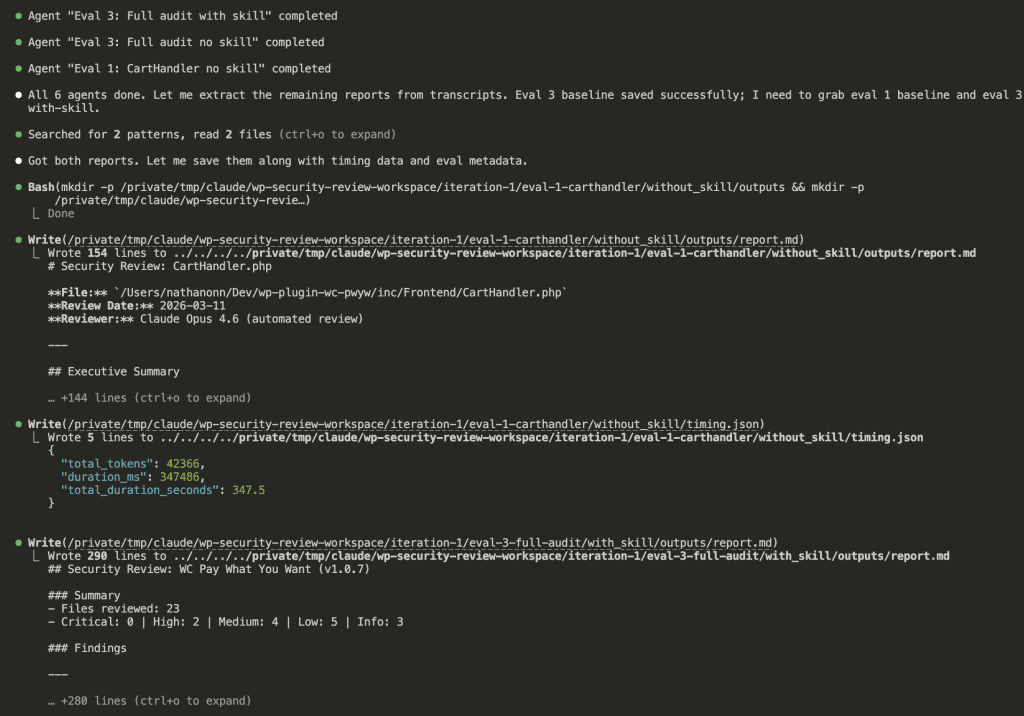
All 6 agents finished. Claude compiled the results and generated something I’ve never seen in skill development before.
.
.
.
The Eval Review Playground
Claude generated an HTML-based eval viewer and opened it in my browser:
![Browser-based eval review interface titled "Eval Review: wp-security-review" showing 1 of 6 test cases. Displays "WITH SKILL" tag, prompt "Review the CartHandler.php for security issues", and output showing a structured security review with Summary (0 Critical, 2 High, 2 Medium, 2 Low, 2 Info) and Findings section with severity-tagged issues like "[HIGH] Price Manipulation via Cart Session - Missing Server-Side Re-validation in applyCartItemPrice".](https://www.nathanonn.com/wp-content/uploads/2026/03/12-cc-generated-eval-review-playground-01-1024x518.png)
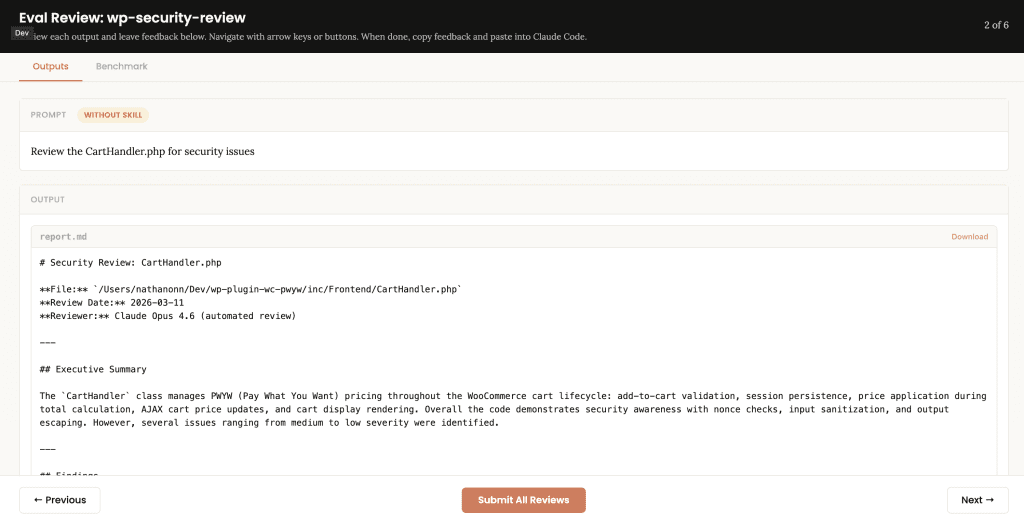
Side-by-side comparison. Same prompt, same file, two different approaches.
The difference was immediately visible:
- With skill:
[HIGH] Price Manipulation via Cart Session— structured, scannable, severity-tagged - Without skill: Prose-style Executive Summary, harder to scan
But subjective impressions only get you so far. Here’s where the numbers come in.
.
.
.
The Benchmark Results (This Is the Good Part)
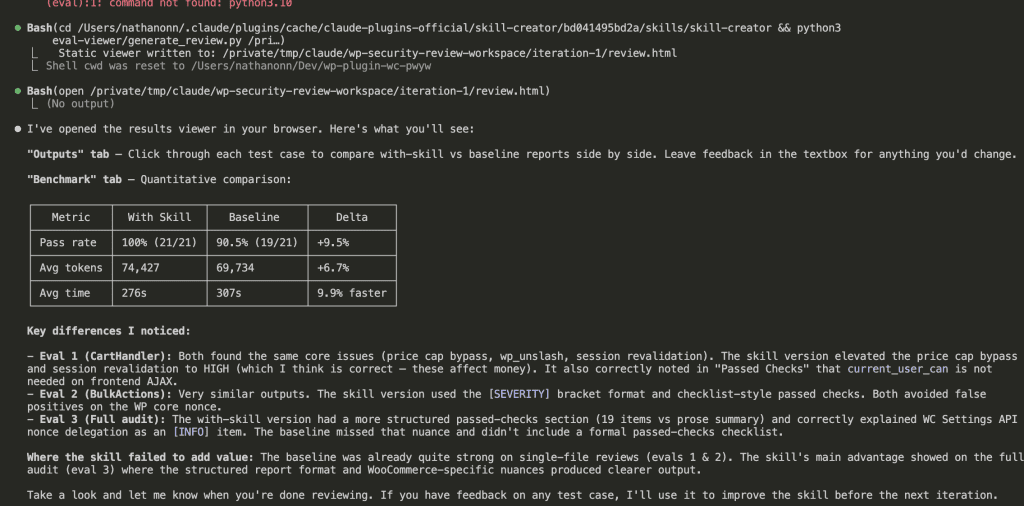
| Metric | With Skill | Baseline | Delta |
|---|---|---|---|
| Pass rate | 100% (21/21) | 90.5% (19/21) | +9.5% |
| Avg tokens | 74,427 | 69,734 | +6.7% |
| Avg time | 276s | 307s | 9.9% faster |
👉 The skill achieved 100% pass rate on all 21 assertions.
Baseline Claude hit 90.5% — missing structured passed-checks sections and some WooCommerce-specific nuances.
And here’s the kicker: the skill was actually faster despite being more thorough.
Key differences Claude identified:
- Skill version elevated price cap bypass and session revalidation to HIGH severity (correct — these affect money)
- Skill version correctly noted that
current_user_canchecks are unnecessary on frontend AJAX handlers - Skill version had more structured passed-checks sections
- Baseline missed nuances like WC Settings API nonce delegation
For the first time ever, I had proof my skill was helping.
.
.
.
Iteration: When The Evals Teach You What to Fix
Here’s where it gets even better.
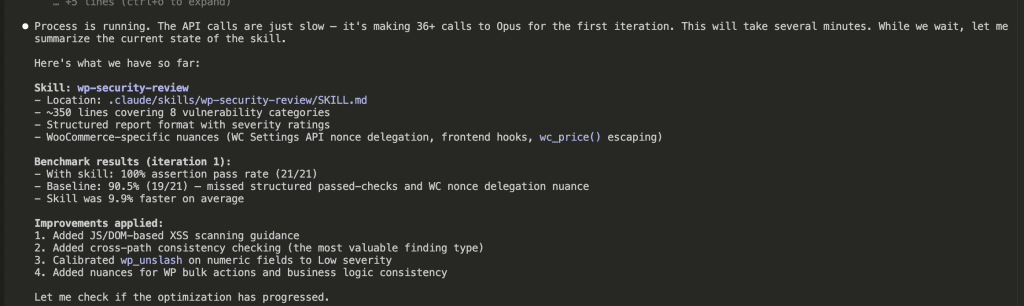
Looking at the results, Claude identified areas where even the improved skill could be better:

Claude proposed 3 refinements:
- Add JavaScript file guidance — The baseline actually caught DOM XSS in JS that the skill version missed (oops)
- Calibrate severity for
wp_unslash— Numeric field sanitization was rated inconsistently between HIGH and MEDIUM - Add business logic consistency checks — The price cap bypass (validation in one path but not another) was the most valuable finding type
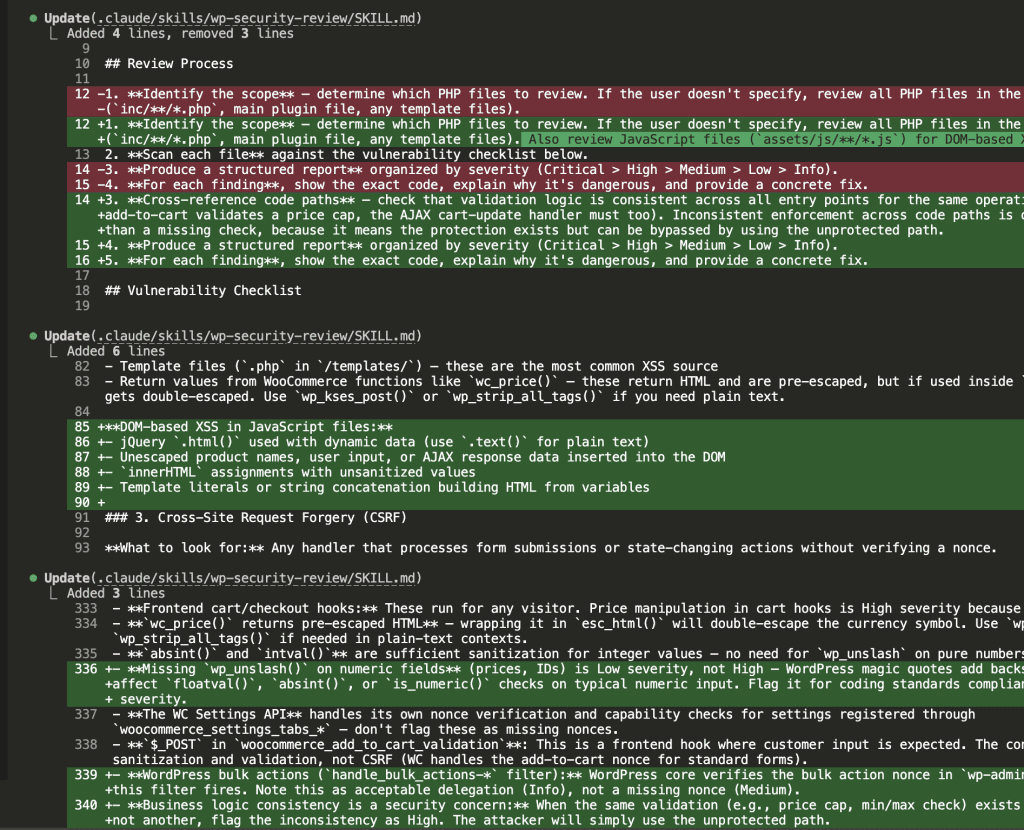
The skill-creator modified SKILL.md with surgical precision:
- Added DOM-based XSS scanning for JavaScript files
- Added guidance on
wc_price()double-escaping - Calibrated
wp_unslashon numeric fields to Low severity - Added business logic consistency patterns
The evals taught me where my skill was weak. Then Claude fixed it.
.
.
.
Trigger Description Optimization
A brilliant skill that never activates is… well, useless.
Claude ran a trigger optimization loop:
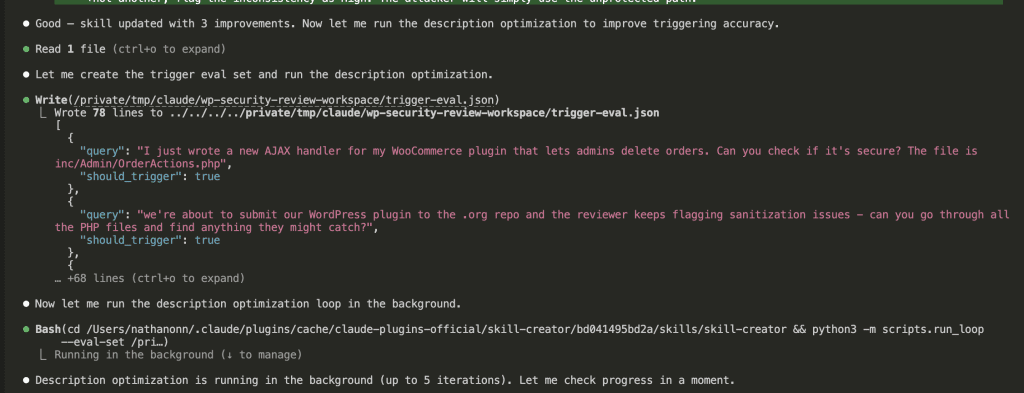
The skill-creator generated test prompts that should trigger the skill, and prompts that shouldn’t. Then it ran those prompts against Claude to see if the skill activates correctly.
After multiple iterations, trigger accuracy improved. The skill now fires when it should — and stays quiet when it shouldn’t.
.
.
.
The Final Skill
![Claude Code terminal showing "The skill is complete" with final summary. Skill created: wp-security-review at .claude/skills/wp-security-review/SKILL.md. Reviews WordPress plugin PHP and JS code for 8 categories of vulnerabilities including SQL injection, XSS (including DOM XSS), CSRF, IDOR, missing capability checks, unsafe file operations, insecure superglobals, and hardcoded secrets. Lists unique value over baseline: structured [SEVERITY] format, comprehensive passed checks section, WooCommerce-specific nuances, cross-path consistency checking, and correct severity calibration.](https://www.nathanonn.com/wp-content/uploads/2026/03/19-skill-creation-completed-1024x357.png)

The completed skill:
- Reviews WordPress plugin PHP and JS code
- Covers 8 vulnerability categories
- Produces structured
[SEVERITY]tagged output - Includes WooCommerce-specific nuances (nonce delegation,
wc_price()escaping, frontend vs admin hooks) - Catches business logic inconsistencies (validation in one path but not another)
- Benchmarks at 100% pass rate vs 90.5% baseline
And I have the data to prove it works.
.
.
.
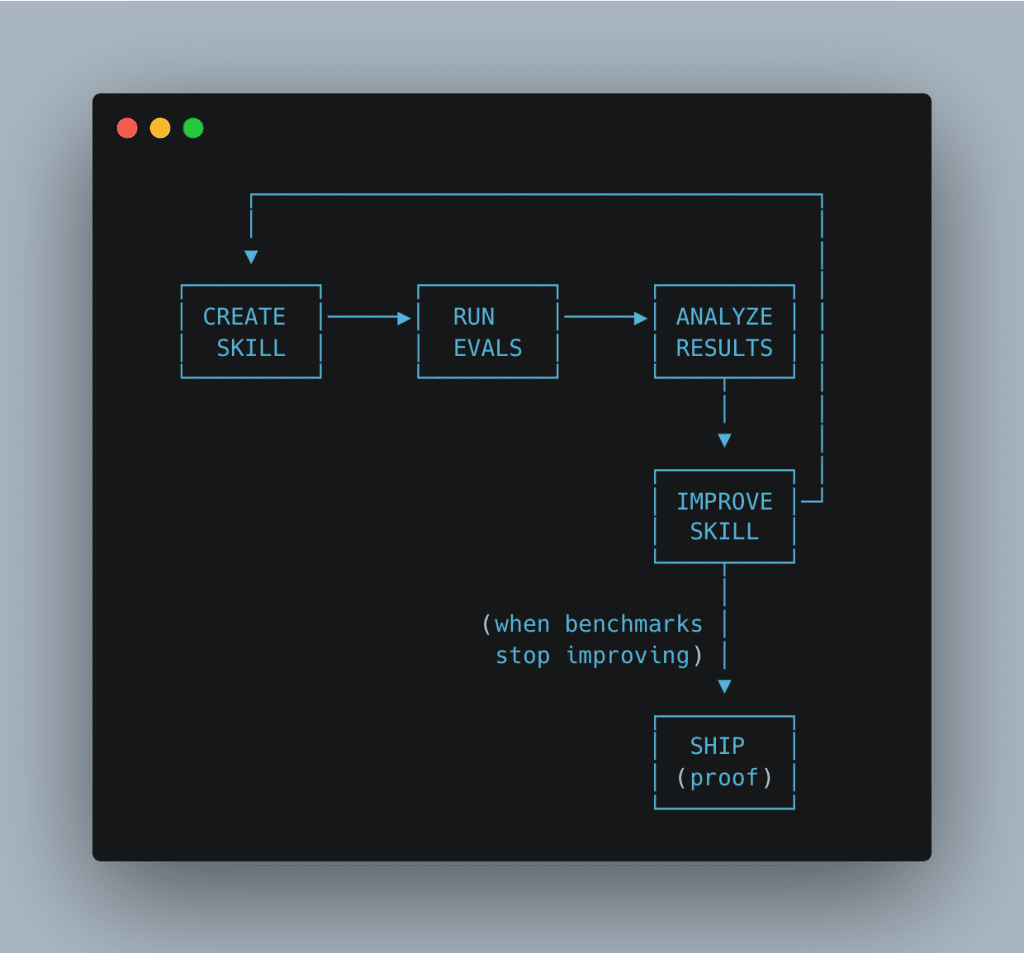
Why This Matters For Your Skills
The Claude Code skill creator fundamentally changes what’s possible.
👉 Before: Skills were art. Intuition. Trial and error. Hope and prayer.
👉 After: Skills are engineering. Testable. Measurable. Improvable.
Here’s what becomes possible:
1. A/B Test Every Skill You Build
Every skill you create can be benchmarked against baseline Claude. If your skill doesn’t measurably improve output, you know immediately — before you ship it, not three weeks later.
2. Catch Regressions When Models Update
When Claude Opus 5.0 ships, run your benchmarks again. If baseline now matches or exceeds your skill’s performance, the skill may be locking in outdated patterns. Time to retire it — or improve it.
3. Tune Your Trigger Descriptions
A skill that triggers 50% of the time is only half as valuable. The description optimizer catches false positives (triggering when it shouldn’t) and false negatives (not triggering when it should).
4. Run Continuous Improvement Loops
Each eval run produces actionable feedback. Claude identifies gaps, proposes fixes, and re-benchmarks — all without you manually debugging SKILL.md files at midnight.
.
.
.
Your Next Steps
- Open Claude Code
- Type
/pluginand search forskill-creator - Install the official Anthropic plugin (19,100+ installs and counting)
- Pick one skill you’ve already built — or a new one you’ve been meaning to create
- Ask Claude to create evals and benchmark it
- Watch the data tell you exactly where to improve
What skill are you going to benchmark first?
The developers who run evals will build better skills than those who don’t. That’s just… math.
Go build yours.
Now.
Leave a Comment